第一部分:引言 (Background)
- 痛点:市面上的平台(知乎/公众号)数据不在自己手里,且排版繁琐。
- 愿景:想要一个“写完即发、无感同步、动静分离”的系统。
- 核心理念:技术服务于内容,而非被技术捆绑。
第二部分:架构设计 (Architecture)
**技术栈选型:
- 写作端:Obsidian + Git (本地管理)
- 服务端:Ubuntu + Docker (环境隔离)
- 生成器:Hugo (极速静态生成)
- 自动化:Python (自定义逻辑处理)
- 存储与展示:Nginx (Web服务) + Alist/Rclone (云备份)
数据流 :本地 Obsidian -> Git Push -> VPS 裸仓库 -> Python 脚本接管 -> Hugo 生成 -> Nginx 展示
核心逻辑

第三部分:核心实现 (The “How”)
环境介绍
目标:在阿里云 Ubuntu 24.04 上搭建基础环境。(个人使用的是阿里的ESC服务器,2 核(vCPU)2 GiB,年租99)
Docker 的应用:
- 简述:为了保持宿主机干净,选择用 Docker 部署 Nginx(Web服务器)和 Alist(云盘挂载)。
- 亮点:通过挂载卷(Volume),让 Nginx 直接读取宿主机的静态文件,实现了容器与本地的灵活交互。 Alist (网盘挂载器):
- 作用:把阿里网盘变成服务器的一个硬盘目录,或者提供 WebDAV 给 Obsidian 备份。
- 部署:在 ECS 上安装 Alist。
- 连接:配置阿里网盘 Token。
- 用途:图、附件、数据库冷备份都扔进阿里网盘,节省 ECS 空间。
Git Server (Gitea 或 纯Git):
- 作用:Obsidian 使用 Git 插件,将笔记 push 到 ECS。
准备工作:
更新系统软件源:apt update && apt upgrade -y
防爆内存设置(SWAP 虚拟内存):由于服务器只有 2GB 内存。如果不设置 Swap(虚拟内存),一旦运行 Docker 或者 AI 脚本稍微占点资源,服务器就会直接卡死或杀掉进程。我们将硬盘划出 4GB 当作备用内存。
执行以下指令:
创建一个 4GB 的文件: fallocate -l 4G /swapfile
设置权限:chmod 600 /swapfile
格式化为交换空间::mkswap /swapfile
启用:swapon /swapfile
永久生效(防止重启后失效):echo '/swapfile none swap sw 0 0' | tee -a /etc/fstab
**调整使用倾向**(让系统尽量先用物理内存,满了再用这个):
|
|
安装核心工具 (Docker, Git, Python)
使用 Docker 来部署服务(Alist, Nginx, 个人网站),这样最干净,不会把系统搞乱。
- 安装 Git 和 Python 包管理工具
apt install git python3-pip python3-venv -y - 安装 Docker (使用官方一键脚本)
curl -fsSL https://get.docker.com | bash - 验证安装
docker --version - 安装 Git 和 Python 工具
apt install git python3-pip python3-venv -y - 安装 Docker
curl -fsSL https://get.docker.com | bash - 验证安装
docker --version - 安装 Alist (网盘挂载工具)
curl -fsSL "https://alist.nn.ci/v3.sh" | bash -s install - 启动 Docker 并设置开机自启
systemctl start dockersystemctl enable docker
注意:安装docker过程中报错,No VM guests are running outdated hypervisor (qemu) binaries on this host.,被墙了,所以直接使用阿里的镜像即可,apt install docker.io -y
Alist使用上述安装同样会报错,建议直接用docker部署,先把 Docker 的下载源换成国内速度快的镜像。
|
|
- 这会创建一个配置文件,告诉 Docker 去国内的服务器下载软件,而不是去国外。
9.启动 Alist (使用 Docker) docker run -d --restart=always -v /etc/alist:/opt/alist/data -p 5244:5244 --name="alist" xhofe/alist:latest
如果看到一串很长的数字/字母ID出现,说明启动成功了。 10.获取管理员密码
10.获取管理员密码 docker logs alist
可以看到Successfully created password: … 11.去阿里云后台打开对应端口即可(入方向,5244端口,0.0.0.0)。访问:
11.去阿里云后台打开对应端口即可(入方向,5244端口,0.0.0.0)。访问: http://IP:5244 即可进入Alist 的登录页面
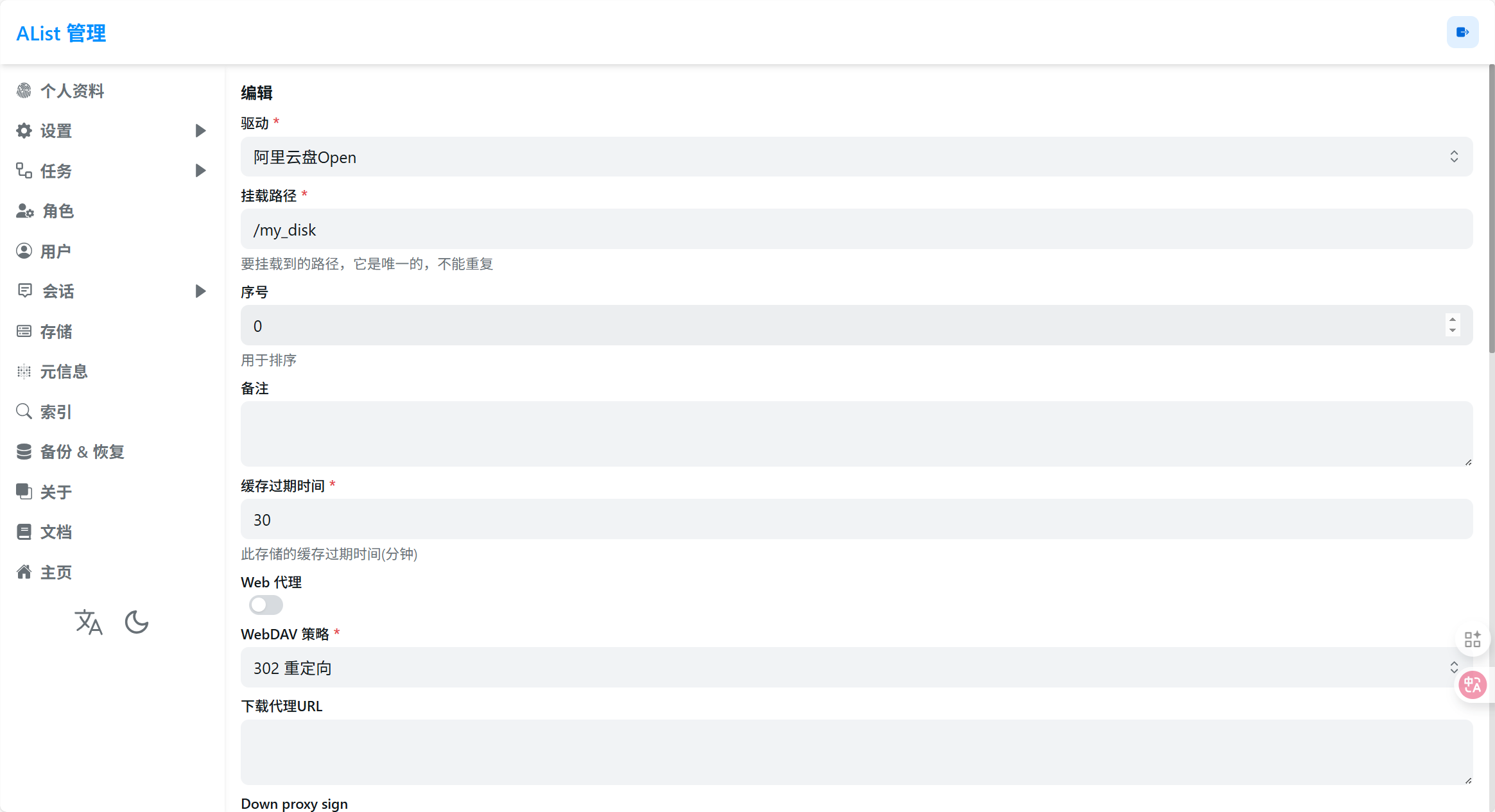
去这里扫码获取Get Aliyundrive Refresh Token | AList Docs 网盘的token用来挂载。 复制token之后,在 Alist 后台添加存储
- 左侧菜单选择 **“存储”。
- 点击 **“添加” 。
- 驱动 (Driver):下拉选择 “阿里云盘 Open” (AliyunDrive Open) —— 选带 Open 的这个,更稳定。
- 挂载路径 (Mount Path):填写
/aliyun(或者你想叫的任何名字,比如/my_disk)。 - 根文件夹ID (Root Folder ID):默认为
root,表示挂载整个网盘。如果只想挂载网盘里的某个文件夹,需要去填那个文件夹的 ID(先不折腾,默认root就行)。 - 刷新令牌 (Refresh Token):粘贴刚才你扫码获取的那一长串字符。
- 其他选项保持默认。
- 点击 “添加”。 添加完成后,状态栏应该显示绿色的 “work”。回到主页即可看到自己的XX网盘。
部署 Nginx (Web 服务器)
1、检查端口占用 (确认 80 端口是空的) lsof -i :80
2、创建简单的测试页面
|
|
3、启动 Nginx 容器
|
|
-p 80:80: 把服务器的 80 端口开放给 Nginx。-v ...: 把刚才创建的/web-site目录挂载进去。以后你只要把生成的网页文件扔进这个文件夹,网站就自动更新了。 注:像刚才给 Alist 开 5244 端口一样,Nginx 需要 80 端口。 注:如果安装了原生Nginx,则需要如下操作把它停掉:
|
|
注:需要的文件家要自己创建,也可直接强制创建,总体操作如下。
|
|
浏览器打开IP即可看到:Hello! My Knowledge System is Running
绑定域名
直接在阿里云申请域名,设置解析,阿里云 。
需要添加两条记录,这样不管用户输 www.你的域名.com 还是 你的域名.com 都能访问。
第一条记录 (主域名):
- 点击 “添加记录” 按钮。
- 记录类型: 选择
A。 - 主机记录: 填
@。 - 记录值: 填你的服务器 IP 。
- TTL: 默认即可。
- 点击 确认。 第二条记录 (www 前缀):
- 再次点击 “添加记录”。
- 记录类型: 选择
A。 - 主机记录: 填
www。 - 记录值: 填你的服务器 IP 。
- 点击 确认。
SSH 免密通道 & 建立 Git 仓库
1、建立仓库文件夹
|
|
解释:--bare 意味着这个仓库没有工作区(看不到具体文件),它专门用来存版本历史,是当“服务器”用的。
2、在 Windows 上生成密钥
安装git,设置邮箱教程很多,暂时略过。
生成密钥:Win + R打开powershell,ssh-keygen -t ed25519 -C "my-blog-key"
接下来会遇到 3 次询问:
- “Enter file in which to save…” -> 直接按回车 (默认路径)。
- “Enter passphrase…” -> 直接按回车 (不设密码,否则自动同步会卡住)。
- “Enter same passphrase again…” -> 直接按回车。
3、获取公钥内容:
输入这个查看公钥:cat $env:USERPROFILE\.ssh\id_ed25519.pub。会显示ssh-ed25519 开头的一串长字符,复制。
- 回到服务器的终端。
- 创建存放钥匙的文件夹
|
|
使用nano或者Vim,nano /root/.ssh/authorized_keys。编辑这个文件,把ssh- 这个公钥复制进去,注意,这个文件是有内容的,在后面另起一行增加即可。
如果顺利,此时ssh root@IP即可免密登录
但是我这里出现了另外的报错:
fatal: detected dubious ownership
这是 Git 在 Windows 上的一个安全机制,只需要执行一条命令把这个目录加入“白名单”即可。
git config --global --add safe.directory G:/yun/yun
接下来推送文件即可:
|
|
注意:@域名 这里可以直接是IP
安装与设置 Hugo
snap install hugo 此安装方式会导致安装老版本,请阅读完这一节再用后面的方式安装
|
|
但是服务器端安装Hugo总是出现问题,索性在本地下载之后使用传上去
点击这个链接下载 PaperMod 的压缩包: 点击这个链接下载主题
语法:scp [本地文件] [服务器用户@IP]:[服务器目录]
scp G:\yun\pm.zip root@ip:/data/my-knowledge-system/hugo-site/themes/
|
|
将文件解压出来之后,改名。
|
|
主题传上去之后发现报错:ERROR => hugo v0.146.0 or greater is required。 即hugo版本过低。点击这个链接下载0.146.0版本 重新卸载安装即可,
|
|
生成网页
|
|
如果由于卸载重新安装找不到hugo,则使用hash -r指令刷新即可
自动化部署 (CI/CD)。
目标: 以后你在 Obsidian 里写完文章,只需要按一下 Git 插件的 Push,服务器就会自动完成以下动作:
- 接收最新笔记。
- 过滤掉私密内容(在写内容的时候可设置发布与不发布)。
- 搬运公开文章到 Hugo 目录。
- 生成新网页。
- 发布到 Nginx。
这需要两个组件:一个Python 脚本,和一个Git 触发器。
1、单独建立中转文件夹:需要一个文件夹,用来临时存放从 Git 仓库里解压出来的所有 Obsidian 笔记(包含私密的)。Python 脚本会从这里挑选文章搬运到 Hugo 里
mkdir -p /data/my-knowledge-system/obsidian-raw2、编写 Python 脚本nano /data/my-knowledge-system/scripts/deploy.py
|
|
3、设置 Git 触发器
nano /data/my-knowledge-system/obsidian-git/blog.git/hooks/post-receive
|
|
给权限:chmod +x /data/my-knowledge-system/obsidian-git/blog.git/hooks/post-receive
注意:publish: true 没这句话的文章会被自动过滤掉,可以用来设置开放和不开放内容。
后续
可以根据个人喜好优化网页,优化展示,增加不同的分区……
云盘保存
存在云盘的哪个位置?
现在的架构是:Linux 服务器 (本地数据) <–> Alist (网关) <–> 阿里云盘 (最终存储)。
- 物理位置:文件最终保存在你的 阿里云盘 服务器上。即使你的服务器爆炸了,文件在阿里云盘里还在。
- 逻辑位置(Alist 中):这取决于你在 Alist 后台添加存储时设置的 “挂载路径”。
- 如果 Alist 里把阿里云盘挂载到了
/(根目录),那文件就在 Alist 的根目录。 - 如果挂载到了
/aliyun,那文件就在/aliyun下。
- 如果 Alist 里把阿里云盘挂载到了
- 对应关系:
- 你在 Alist 看到的目录结构,一一对应 你阿里云盘 App 里的目录结构(除非挂载时指定了某个子文件夹 ID)。
- 你在 Alist 看到的目录结构,一一对应 你阿里云盘 App 里的目录结构(除非挂载时指定了某个子文件夹 ID)。
怎么把服务器文件保存到云盘?
因为 Alist 是运行在 Docker 容器里的,而文件(比如 Obsidian 笔记、Hugo 网站)是在服务器宿主机上的 /data 目录里。Alist 容器默认是“看不见”宿主机上的文件的。
要把服务器文件传给 Alist(进而传到阿里云盘),最专业、最自动化的方案是使用 Rclone。
Rclone 就像是一个“万能搬运工”,运行在服务器上,一手拿着本地文件,一手连着 Alist 的 WebDAV 接口,把文件“搬”过去。
1、 安装 Rclone apt install rclone -y
2、配置连接 (连接到 Alist) 我们需要告诉 Rclone 怎么找到 Alist。运行下面这行命令(这会生成一个配置文件):
- 输入
rclone config回车。 - 输入
n(New remote)。 - name 输入
alist。 - Storage 选
WebDAV(输入对应的数字,通常是 40 左右,找一下 WebDAV)。 url输入http://127.0.0.1:5244/dav。vendor选other。user输入admin。password输入y,然后输入 Alist 密码(输两次)。- 后面一路回车(默认),最后输
y确认退出。
3、手动备份测试:配置好后,试着把知识库备份到云盘。
假设在 Alist 里有一个挂载好的XX云盘目录叫 /aliyun(我的是my_disk)。我们想把本地的 /data/my-knowledge-system 备份到云盘的 我的服务器备份 文件夹。
执行命令:
语法: rclone copy 本地源 远程名:远程路径
rclone copy /data/my-knowledge-system alist:/aliyun/我的服务器备份
如果顺利会看到下面的样子

==一旦上面的流程打通,就可以设置自动化备份到云盘==
- 输入
crontab -e。 - 直接添加这一行:
0 3 * * * /usr/bin/rclone sync /data/my-knowledge-system alist:/my_disk/我的服务器备份 >> /var/log/backup.log 2>&1==每天凌晨 3 点,自动把服务器数据同步到云盘的my_disk/我的服务器备份里==
注:Alist 网页版可以通过http://IP:5244访问。
第四部分 踩坑
中文乱码。Windows (GBK) 与 Linux (UTF-8) 在 Git 推送时的编码冲突,使用英文合适。
Hugo 版本依赖:PaperMod 主题对 Hugo 新版的要求。
网络问题:服务器无法连接 GitHub 时,通过本地下载 + SCP 上传。
时间问题:Hugo 的“保护机制”,Hugo 默认有一个规则:“如果一篇文章的日期在『未来』,那它肯定还没发生,所以我不能发布,为了避免这种情况,在deploy.py中需要设置run_command("hugo --buildFuture") 允许未来发布。
注:在实测中,单独修改时间2025年可以发布,实时时间无法发布,可能与服务器时间有关,修改时间之后解决。
代码乱码问题:本来使用 ```1``` 这种格式放置代码段,但是出现排版错误,如下。经检查,是由于未定义代码类型的问题,只需定义python即可。```python```

图片的位置问题:本地端设置为“基于仓库跟目录的绝对路径”。需要同时配置好本地,服务器,网页的图片路径问题,是用脚本和钩子就可以完成全部的自动化。此时图片资源文件夹为:99_Assets
| 物理位置 (Path) | 图片引用语法 | |
|---|---|---|
| 本地端 | 99_Assets\pic.png |  |
| 服务器 | /obsidian-raw/99_Assets/pic.png | 文件还没变成网页 |
| 网页 (Nginx/Web) | /web-site/99_Assets/pic.png |  |
举例说明:在网页端,文章网址是 yunfei.life/tech/serverless/。
- 如果写
99_Assets/pic.png(不带斜杠),浏览器会以为图片在文章的隔壁,也就是yunfei.life/tech/serverless/99_Assets/。这是错的。 - 如果写
/99_Assets/pic.png(带斜杠),浏览器会直接去根目录找,也就是yunfei.life/99_Assets/。这才是对的。
所以需要在deploy.py中设置去根目录中寻找: assets_src = os.path.join(RAW_DIR, “99_Assets”)
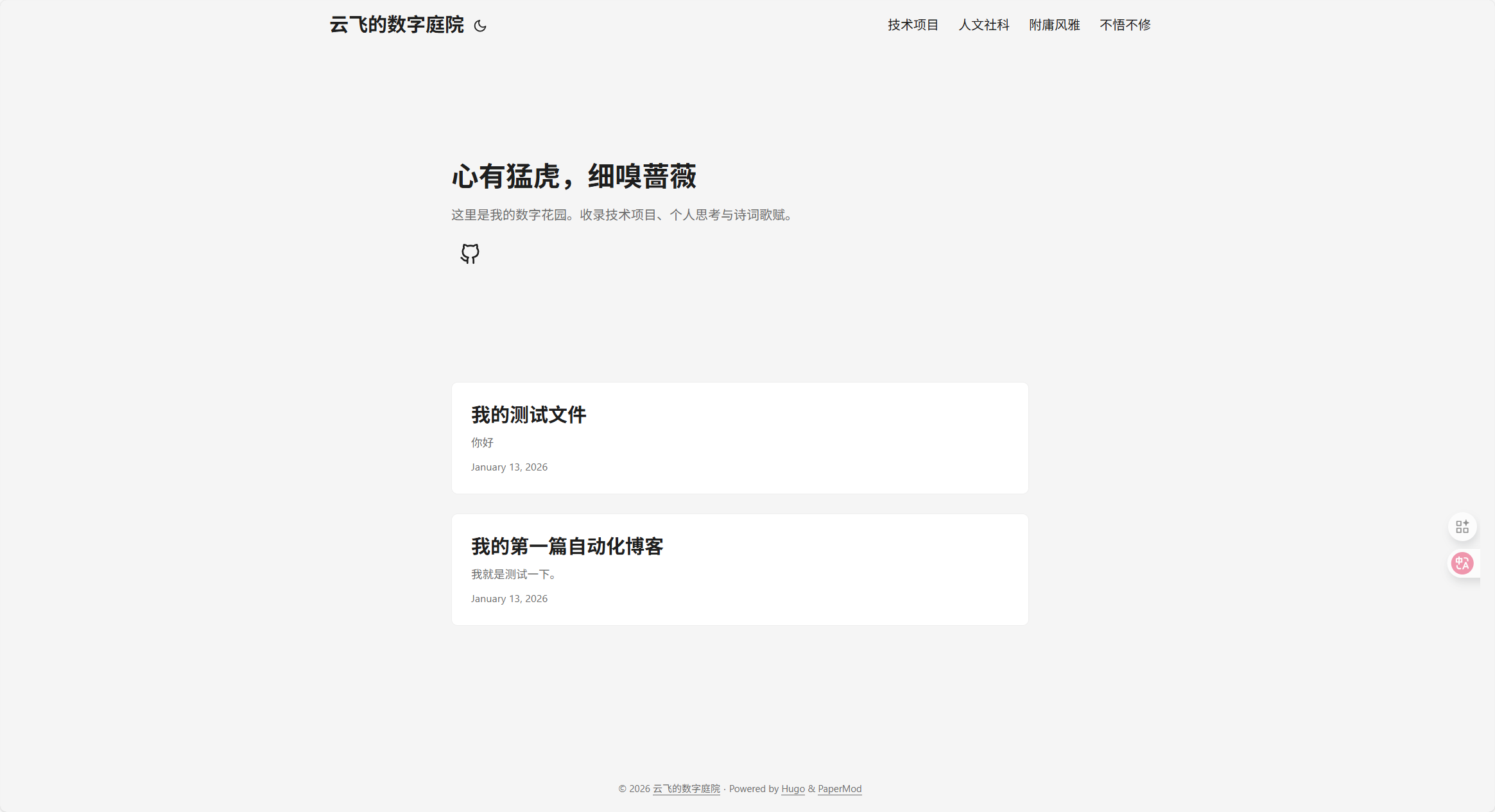
第五部分:成果展示与结语
整理一套简单的数据流,核心是为了记录自己的数据,曾尝试过很多的记录策略,在数字时代,有一个属于自己的地方便于记录,整理。 算法推荐横行、平台审核无处不在的时代,有那么一点点的自由都成为了奢侈。而大模型的快速发展,又让文字的产生越来越没有成本,在公共传媒平台,但凡可以发出来的透露一点挣扎和心意的文字都已经是一种奢侈了(知乎,微信,微博,抖音,哪个不是如此?)。所以有了它。在这里,没有访客记录,没有点赞,有的只是记录,思考和交流,悉达多说:我会思考,嗯,是的。
就做一个沉浸在自己世界的的“混子”,不胜潇洒。