-
背景:在油管/B站有非常多的UP主,有非常多的高质量信息,访谈/播客等等,希望可以将其整理成文字稿,一方面填充自己的文件库,另一方面学习高质量的认知等
-
问题:显然,视频数据量太大不足以看得完,且听的效率要低于阅读,且众多英文视频对于英文听力不友好的人过于困难。
-
策略:构建一整套信息流,希望可以将对应UP主的视频分门别类下载音频,转录成文字稿,并提供总结,金句,重要片段,反脆弱的片段。
-
服务端:Ubuntu Linux (无 Root 权限,实验室内网,存在透明网关防火墙)
-
客户端:Windows 11 (运行 Clash 代理,具备外网访问能力)
-
目标:自动化下载 YouTube 指定频道视频 -> WhisperX 分离人声转录 -> Qwen 大模型翻译/润色 -> 生成汇总文档。
可行思考:可通过分析知识类高流量爆款UP主的文稿,批量收集,做一个微调模型,为自己的文稿润色,为后续做自媒体提供些许帮助。
一、 核心网络策略:反向 SSH 隧道 (Reverse SSH Tunneling)#
由于服务器无法直接访问 YouTube 和 HuggingFace(国外),我们必须利用本地 Windows 电脑作为“跳板”。
1.1 初始#
1.2 隧道命令(Windows 端)#
PowerShell
1
2
|
# 语法:ssh -R <服务器端口>:<本地局域网IP>:<Clash端口> <用户名>@<服务器IP>
ssh -R 7899:本地IP:7890 jiangyun@服务器IP
|
二、 视频下载模块 (yt-dlp)#
网络打通后,面临身份验证和 SSL 握手问题。
2.1 遇到的问题#
-
Bot 验证失败:YouTube 检测到数据中心 IP(Clash 节点),要求验证。
-
SSL EOF 报错:Python 的 ssl 模块在高并发下通过 SSH 隧道握手时极不稳定。
-
Node.js 缺失:无法计算 YouTube 的 n 参数签名。
2.2 解决方案#
-
**节点:在 Clash 端手动切换节点,避开拥挤节点。
-
身份伪装:
- 从浏览器导出 Netscape 格式的
cookies.txt 并上传至服务器。
- 指定服务器上具体的
node 路径解决签名计算。
-
最终参数组合(写入脚本):
Bash
1
2
|
PROXY_URL="http://127.0.0.1:7899" # 走 SSH 隧道的新端口
YTDLP_ARGS="--proxy $PROXY_URL --cookies cookies.txt --force-ipv4 --no-check-certificates --js-runtimes node:/path/to/node"
|
2.3 转录模型#
需要下载转录模型以及确定说话人的模型:
1
2
3
|
export http_proxy="http://127.0.0.1:7899"
export https_proxy="http://127.0.0.1:7899"
unset HF_ENDPOINT # 确保不走镜像,走官网最稳
|
1
2
3
4
5
6
|
huggingface-cli download Systran/faster-whisper-large-v3 --token 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
# 下载声纹分割模型
huggingface-cli download pyannote/segmentation-3.0 --token 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
# 下载声纹聚类模型
huggingface-cli download pyannote/speaker-diarization-3.1 --token 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
|
找到下载在缓存中的模型路径放入脚本中的WHISPER_MODEL即可:ls -d /home/jiangyun/.cache/huggingface/hub/models--Systran--faster-whisper-large-v3/snapshots/*/
三、 大模型下载策略:从 HuggingFace 到 ModelScope#
我们需要下载 Qwen/Qwen1.5-14B-Chat(约 28GB),一方面修复转录过程中的错误,一方面做翻译。
国内镜像 (ModelScope)#
四、 自动化脚本整合#
最后,我们将所有组件串联为两个脚本。
4.1 目录结构#
Plaintext
1
2
3
4
5
6
7
8
|
/home/data2/jiangyun/you/
├── 3_channels_batch.sh # 主控脚本(负责逻辑控制)
├── qwen_translate.py # AI处理脚本(负责调用模型)
├── cookies.txt # 身份凭证
└── UP_Downloads/ # 自动生成的输出目录
├── WhynotTV/
├── 十三邀/
└── ...
|
4.2 脚本逻辑 (3_channels_batch.sh)#
-
环境自检:检查 Cookies 和 Python 脚本是否存在。
-
代理管理:
-
流程控制:
五、 经验总结 (Key Takeaways)#
-
遇到端口占用且无 Root 权限时:不要死磕 kill 进程,直接换端口是最快解决方案。
-
SSH 隧道不稳定时:尝试将 SSH 绑定到局域网真实 IP 而非 127.0.0.1,可以规避很多 Windows 本地的网络策略限制。
-
下载大模型时:
- 如果服务器在国内且无外网:首选 ModelScope (魔搭),走国内内网直连。
- 不要试图用梯子去访问国内镜像站(hf-mirror),会被反向屏蔽。
-
路径管理:脚本运行报错 No such file 时,99% 是因为相对路径问题(如 cookies.txt 在上一级目录),务必确保执行目录正确。
六、油管视频#
6.1 配置cookies.txt#
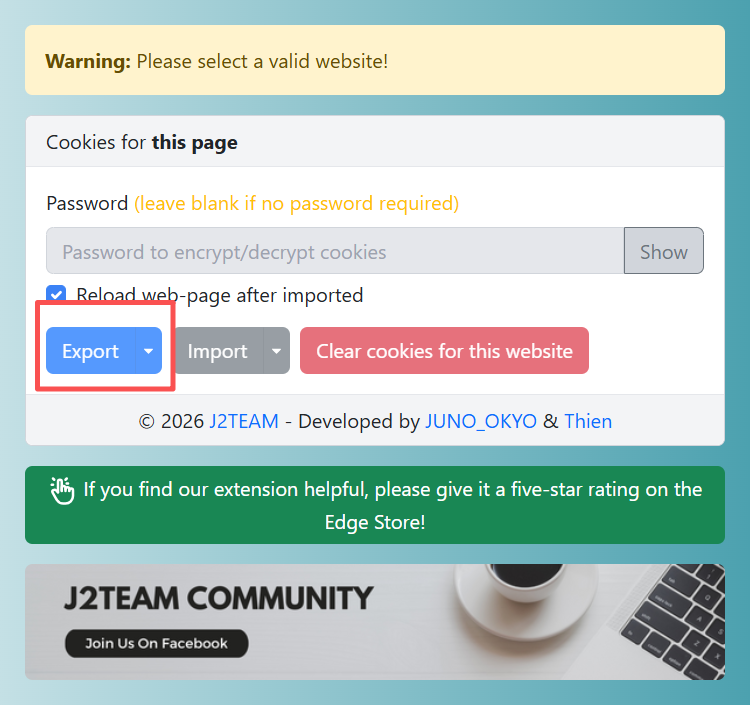
使用插件获取到cookies。然后上传到对应文件夹即可,这里笔者使用的是J2TEAM Cookies。
 导出json文档,使用下面的代码转成txt即可
导出json文档,使用下面的代码转成txt即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import json
# 读取 JSON cookies
with open(r'./www.youtube.com_22-01-2026 (4).json', 'r', encoding='utf-8') as f:
data = json.load(f)
cookies = data['cookies'] # 提取 cookies 数组
# 写入 Netscape 格式
with open(r'./cookies.txt', 'w', encoding='utf-8') as f:
f.write("# Netscape HTTP Cookie File\n")
f.write("# This is a generated file! Do not edit.\n\n")
for cookie in cookies:
domain = cookie.get('domain', '')
flag = 'TRUE' if domain.startswith('.') else 'FALSE'
path = cookie.get('path', '/')
secure = 'TRUE' if cookie.get('secure', False) else 'FALSE'
expiration = str(int(cookie.get('expirationDate', 0)))
name = cookie.get('name', '')
value = cookie.get('value', '')
f.write(f"{domain}\t{flag}\t{path}\t{secure}\t{expiration}\t{name}\t{value}\n")
print(f"转换完成!共转换 {len(cookies)} 个 cookies")
print(f"输出文件: cookies.txt")
|
七、新思路#
上述思路总是会被youtube认为是机器人从而封掉IP。想办法一劳永逸解决机器人验证的问题。
完全模拟浏览器环境。
7.1 获取Visitor Data#
用浏览器打开 YouTube 网页时,YouTube 的前端 JS 代码会运行一堆复杂的加密运算,根据浏览器指纹生成这串 Base64 编码的 ID。
浏览器打开一个油管视频。按F12,把下面代码复制进控制台(控制台 最下面 > 后面)。回车即可看到一串字符。把它复制下来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// === 从这里开始复制 ===
var v_data = "未找到";
var p_token = "未找到";
try {
// 尝试获取 visitor_data
if (window.ytcfg && window.ytcfg.data_) {
v_data = window.ytcfg.data_.VISITOR_DATA || "未找到";
}
// 尝试获取 po_token
if (window.ytcfg && window.ytcfg.data_ && window.ytcfg.data_.PAGE_CL_) {
p_token = window.ytcfg.data_.PAGE_CL_.po_token || "未找到";
} else if (window.yt && window.yt.config_ && window.yt.config_.PAGE_CL) {
var match = window.yt.config_.PAGE_CL.match(/po_token":"(.*?)"/);
if(match) p_token = match[1];
}
} catch (e) {}
console.log("\n\n⬇️⬇️⬇️ 请复制下面这行红色或绿色的字 ⬇️⬇️⬇️\n");
console.log("visitor_data=" + v_data + ";po_token=" + p_token);
console.log("\n⬆️⬆️⬆️ 复制上面这一整行 ⬆️⬆️⬆️\n\n");
// === 复制结束 ===
|
7.2 获取User-Agent#
一串声明自己软件环境的字符串(如 Chrome/120 Windows 10),模拟软件型号。
同样的,控制台输入navigator.userAgent 回车。把输出的一串字符复制下来
使用如下指令测试。
1
2
|
yt-dlp -v \ --proxy http://127.0.0.1:7899 \ --cookies cookies.txt \ --user-agent "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36" \ --js-runtimes "node:$NODE_PATH" \ --extractor-args "youtube:player_client=web;visitor_data=复制7.1得到的内容" \
https://www.youtube.com/shorts/oo_TZRdxn-s
|
正常情况下会开始下载视频。如果不行,更换节点即可
八、代码#
分两块,下载音频和批量转录
务必找到代码最上面的 MY_UA 和 MY_VISITOR_DATA
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
#!/bin/bash
# ================= 配置区域 (请填入你的信息) =================
# 1. 频道列表
CHANNELS=(
"https://www.youtube.com/@xiaojunpodcast"
)
BASE_DIR="./UP_Downloads"
PROXY_URL="http://127.0.0.1:7899"
COOKIES_FILE="cookies.txt"
# 🔥 2. node 路径 (请确认你的路径是否一致)
# 使用 'which node' 命令可以查看
NODE_PATH="/home/jiangyun/.nvm/versions/node/v20.19.6/bin/node"
# 🔥 3. 你的浏览器 User-Agent (必须填入你刚才验证成功的那串)
# 格式示例: "Mozilla/5.0 (Windows NT 10.0...)"
MY_UA="【请在此处粘贴你的 User-Agent,保留双引号】"
# 🔥 4. 你的入场券 Visitor Data (必须填入你刚才验证成功的那串)
# 格式示例: "CgtDVnB0eUF2ZEVX..."
MY_VISITOR_DATA="【请在此处粘贴你的 visitor_data 字符串,保留双引号】"
# ==========================================================
# 构造参数数组 (使用数组彻底解决空格和特殊字符问题)
YTDLP_ARGS=(
--proxy "$PROXY_URL"
--cookies "$COOKIES_FILE"
--user-agent "$MY_UA"
--js-runtimes "node:$NODE_PATH"
--extractor-args "youtube:player_client=web;visitor_data=$MY_VISITOR_DATA"
--force-ipv4
--no-check-certificates
--no-warnings
--socket-timeout 30
)
echo "=========================================="
echo "📥 [进货员] 启动: 全套伪装下载模式"
echo "=========================================="
for CHANNEL_URL in "${CHANNELS[@]}"; do
echo ""
echo ">>> 分析频道: $CHANNEL_URL"
# 获取 UP 主名 (重试 3 次)
for i in {1..3}; do
UPLOADER_NAME=$(yt-dlp "${YTDLP_ARGS[@]}" --playlist-end 1 --print "%(uploader)s" "$CHANNEL_URL" 2>/dev/null)
[ -n "$UPLOADER_NAME" ] && break
sleep 2
done
if [ -z "$UPLOADER_NAME" ]; then
echo "⚠️ 无法获取频道信息(可能被风控或网络超时),跳过。"
continue
fi
SAFE_UPLOADER=$(echo "$UPLOADER_NAME" | sed 's/[<>:"/\\|?*]//g' | sed 's/\s\+/_/g')
echo "📂 目标目录: $SAFE_UPLOADER"
# 拉取列表
LIST_FILE="${SAFE_UPLOADER}_list.txt"
if [ ! -f "$LIST_FILE" ]; then
echo " 📋 正在获取视频列表..."
yt-dlp "${YTDLP_ARGS[@]}" --flat-playlist --print "%(id)s" "$CHANNEL_URL" > "$LIST_FILE"
fi
# 循环下载
while IFS= read -r VIDEO_ID; do
[ -z "$VIDEO_ID" ] && continue
VIDEO_URL="https://www.youtube.com/watch?v=$VIDEO_ID"
# 获取标题
TITLE=$(yt-dlp "${YTDLP_ARGS[@]}" --get-title "$VIDEO_URL" 2>/dev/null)
[ -z "$TITLE" ] && TITLE="$VIDEO_ID"
SAFE_TITLE=$(echo "$TITLE" | sed 's/[<>:"/\\|?*]//g' | sed 's/\s\+/ /g')
SAFE_TITLE=${SAFE_TITLE:0:80}
VIDEO_DIR="$BASE_DIR/$SAFE_UPLOADER/$SAFE_TITLE"
mkdir -p "$VIDEO_DIR"
AUDIO_FILE="$VIDEO_DIR/audio.m4a"
INFO_FILE="$VIDEO_DIR/info.txt"
if [ -f "$AUDIO_FILE" ]; then
# echo " ⏭️ 已存在: $SAFE_TITLE"
continue
fi
echo " ⬇️ 正在下载: $SAFE_TITLE"
# 使用数组参数进行下载
if yt-dlp "${YTDLP_ARGS[@]}" -f "bestaudio[ext=m4a]/bestaudio/best" -o "$AUDIO_FILE" "$VIDEO_URL"; then
# ✅ 关键:写入元数据供转录脚本使用
echo "URL=$VIDEO_URL" > "$INFO_FILE"
echo "TITLE=$TITLE" >> "$INFO_FILE"
# 随机休息 10-30 秒 (保护这来之不易的成功)
SLEEP_TIME=$((10 + RANDOM % 20))
echo " 😴 下载成功,休息 ${SLEEP_TIME} 秒..."
sleep $SLEEP_TIME
else
echo " ❌ 下载失败,稍后继续"
sleep 5
fi
done < "$LIST_FILE"
done
echo "🎉 所有频道下载扫描完成!"
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
|
#!/bin/bash
# ================= 配置区域 =================
export HF_TOKEN="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"
BASE_DIR="./UP_Downloads"
# 模型配置
WHISPER_MODEL="/home/jiangyun/.cache/huggingface/hub/models--Systran--faster-whisper-large-v3/snapshots/edaa852ec7e145841d8ffdb056a99866b5f0a478/"
DEVICE="cuda"
COMPUTE_TYPE="float16"
# 强制离线,确保不联网
unset http_proxy https_proxy all_proxy
export HF_HUB_OFFLINE=1
unset HF_ENDPOINT
echo "=========================================="
echo "🍳 [厨师] 启动: 全盘扫描并转录 (兼容旧存量)"
echo "=========================================="
while true; do
# ----------------------------------------------------
# 🔥 核心逻辑修正:无差别扫描所有 audio.m4a
# ----------------------------------------------------
# 1. 找出所有 audio.m4a
# 2. 筛选出同目录下没有 full_document.txt 的
# 3. 只取第 1 个作为当前任务
TARGET_FILE=$(find "$BASE_DIR" -type f -name "audio.m4a" | while read audio_path; do
dir_path=$(dirname "$audio_path")
if [ ! -f "$dir_path/full_document.txt" ]; then
echo "$audio_path"
break # 找到一个就立刻跳出,开始干活,别贪多
fi
done | head -n 1)
# 如果没找到任务
if [ -z "$TARGET_FILE" ]; then
echo "💤 所有存量和新量任务已清空,等待 [进货员] 上新... (10秒轮询)"
sleep 10
continue
fi
# 提取目录路径
TARGET_DIR=$(dirname "$TARGET_FILE")
DIR_NAME=$(basename "$TARGET_DIR")
echo "------------------------------------------"
echo "🔍 锁定任务: $DIR_NAME"
# 定义文件路径
AUDIO_FILE="$TARGET_FILE"
JSON_FILE="$TARGET_DIR/audio.json"
RAW_TEXT_FILE="$TARGET_DIR/transcript_raw.txt"
TRANS_FILE="$TARGET_DIR/transcript_qwen.txt"
FULL_DOC="$TARGET_DIR/full_document.txt"
INFO_FILE="$TARGET_DIR/info.txt"
# ----------------------------------------------------
# 1. WhisperX 转录 (显卡繁重工作)
# ----------------------------------------------------
if [ ! -f "$JSON_FILE" ]; then
echo " 🎙️ WhisperX 转录中..."
if ! CUDA_VISIBLE_DEVICES=0 whisperx "$AUDIO_FILE" \
--model "$WHISPER_MODEL" --device "$DEVICE" --compute_type "$COMPUTE_TYPE" \
--output_format json --output_dir "$TARGET_DIR" \
--task transcribe --hf_token "$HF_TOKEN" \
--diarize --min_speakers 1 --max_speakers 3 > "$TARGET_DIR/whisper.log" 2>&1; then
echo " ❌ 转录崩溃,标记失败并跳过。"
# 生成一个错误文档,防止脚本下次死循环一直卡在这个文件上
echo "错误:WhisperX 转录失败,请检查 whisper.log" > "$FULL_DOC"
continue
fi
fi
# ----------------------------------------------------
# 2. 提取文本 (瞬间完成)
# ----------------------------------------------------
if [ ! -f "$RAW_TEXT_FILE" ]; then
python3 -c "import json; data=json.load(open('$JSON_FILE')); open('$RAW_TEXT_FILE','w').write(''.join([f\"[{s.get('speaker','UNK')}] {s['text'].strip()}\n\" for s in data['segments']]))"
fi
# ----------------------------------------------------
# 3. Qwen 翻译 (CPU/GPU工作)
# ----------------------------------------------------
if [ ! -f "$TRANS_FILE" ]; then
echo " 🤖 Qwen 翻译中..."
python3 qwen_translate.py "$RAW_TEXT_FILE" "$TRANS_FILE"
fi
# ----------------------------------------------------
# 4. 元数据读取 (兼容旧存量视频!)
# ----------------------------------------------------
if [ -f "$INFO_FILE" ]; then
# 如果是新下载的,有 info.txt,直接读
CUR_URL=$(grep "^URL=" "$INFO_FILE" | cut -d= -f2-)
CUR_TITLE=$(grep "^TITLE=" "$INFO_FILE" | cut -d= -f2-)
else
# 🔥 如果是旧存量,没有 info.txt,执行降级策略
echo " ⚠️ 未发现元数据(旧存量),使用目录名作为标题。"
CUR_URL="存量视频(无原始链接)"
# 直接用文件夹名字当标题
CUR_TITLE="$DIR_NAME"
fi
# ----------------------------------------------------
# 5. 生成最终文档
# ----------------------------------------------------
echo " 📄 生成最终文档..."
cat > "$FULL_DOC" <<EOF
==================================================
标题: $CUR_TITLE
链接: $CUR_URL
处理时间: $(date)
==================================================
【Qwen 总结】
$(cat "$TRANS_FILE")
==================================================
【Whisper 原文】
$(cat "$RAW_TEXT_FILE")
EOF
echo " ✅ 任务完成!清理缓存..."
# 可选:清理中间大文件节省空间 (如果硬盘够大可以注释掉)
# rm "$TARGET_DIR/audio.json"
done
|
